Processing pipeline
An advanced semantic-aware pipeline for large-scale web data processing

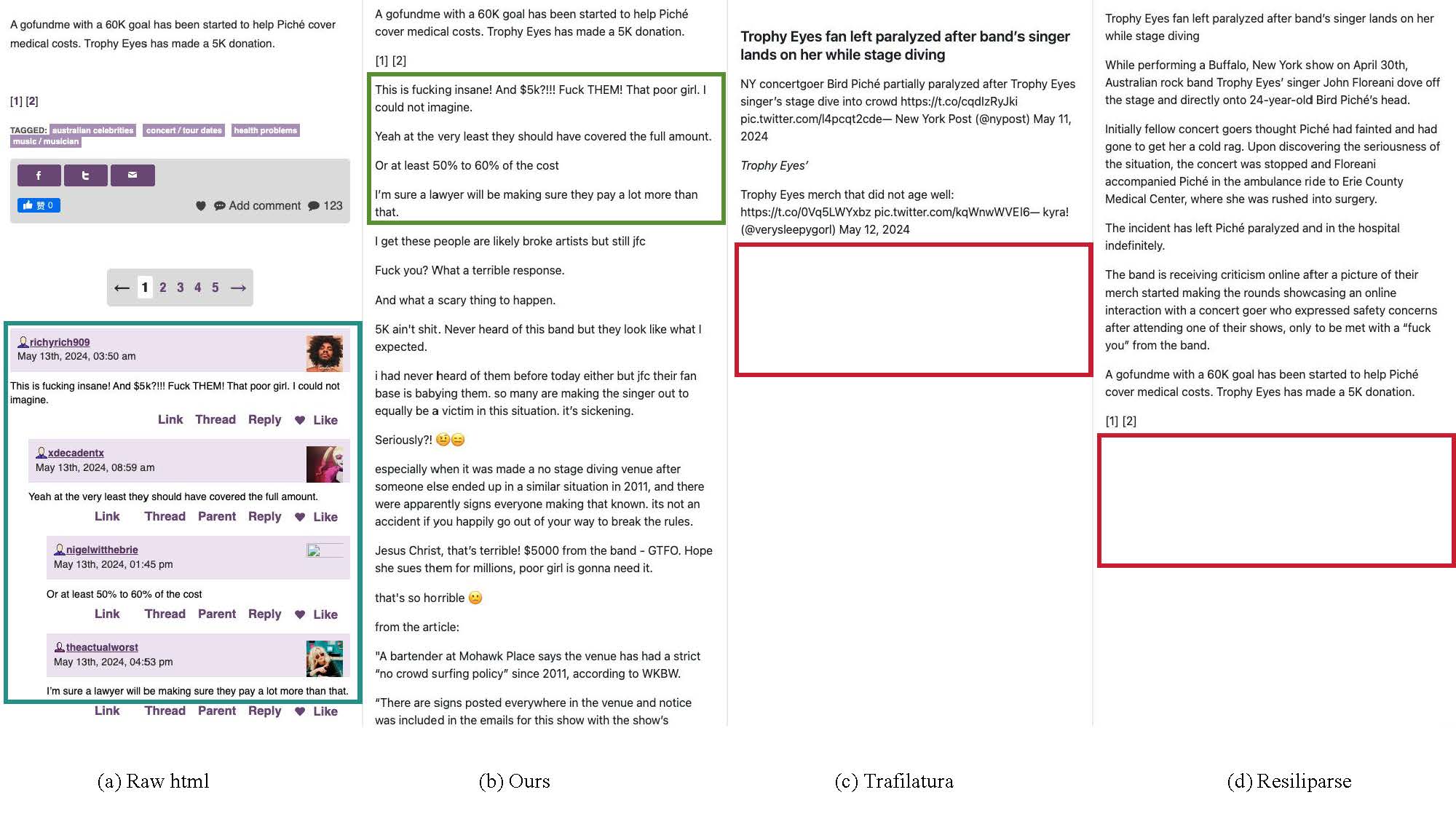
High-quality main content
High-fidelity main content extracted from diverse Common Crawl pages, including challenging types like forums, Q&A sites, and pages with tables or formulas.
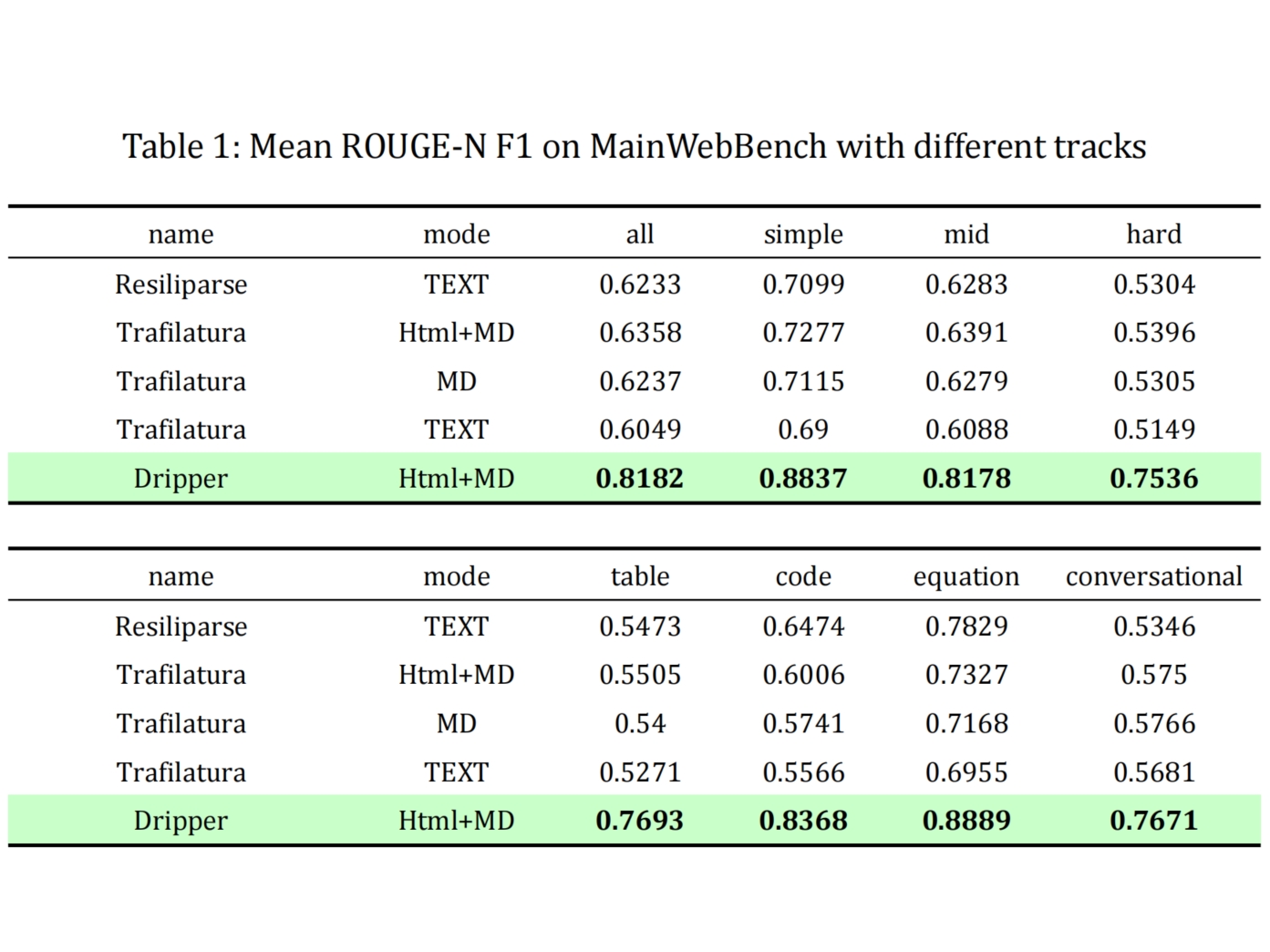
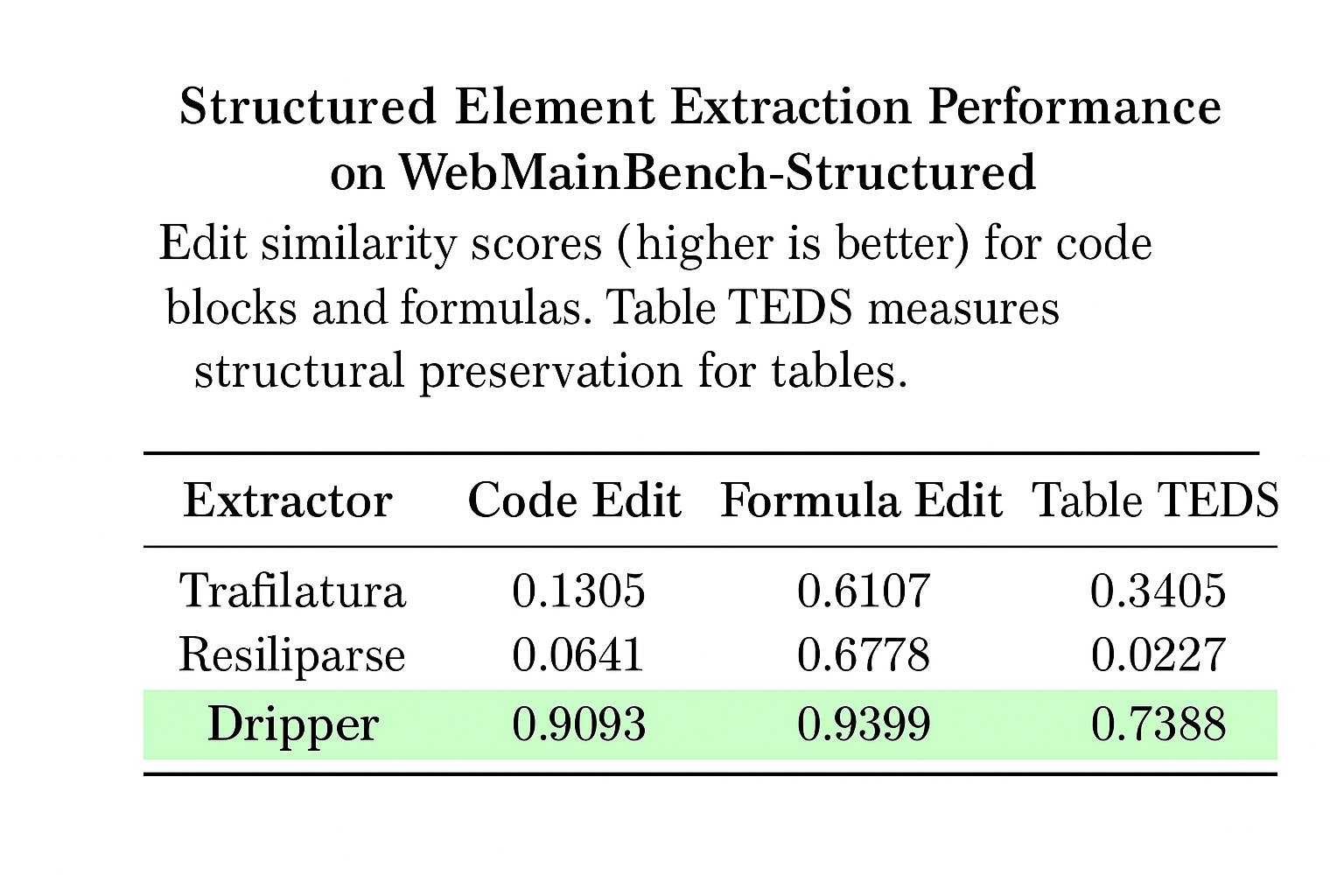
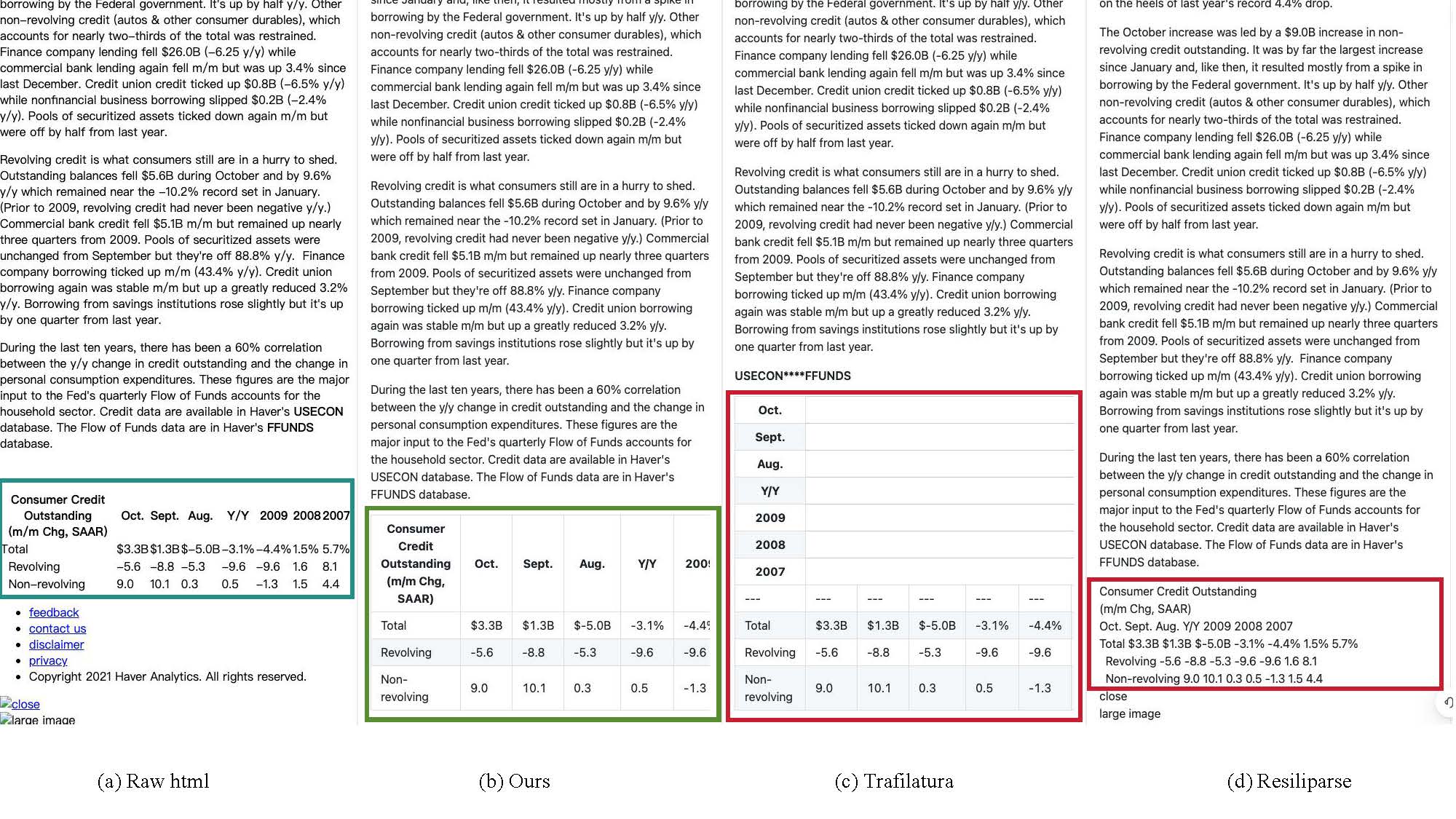
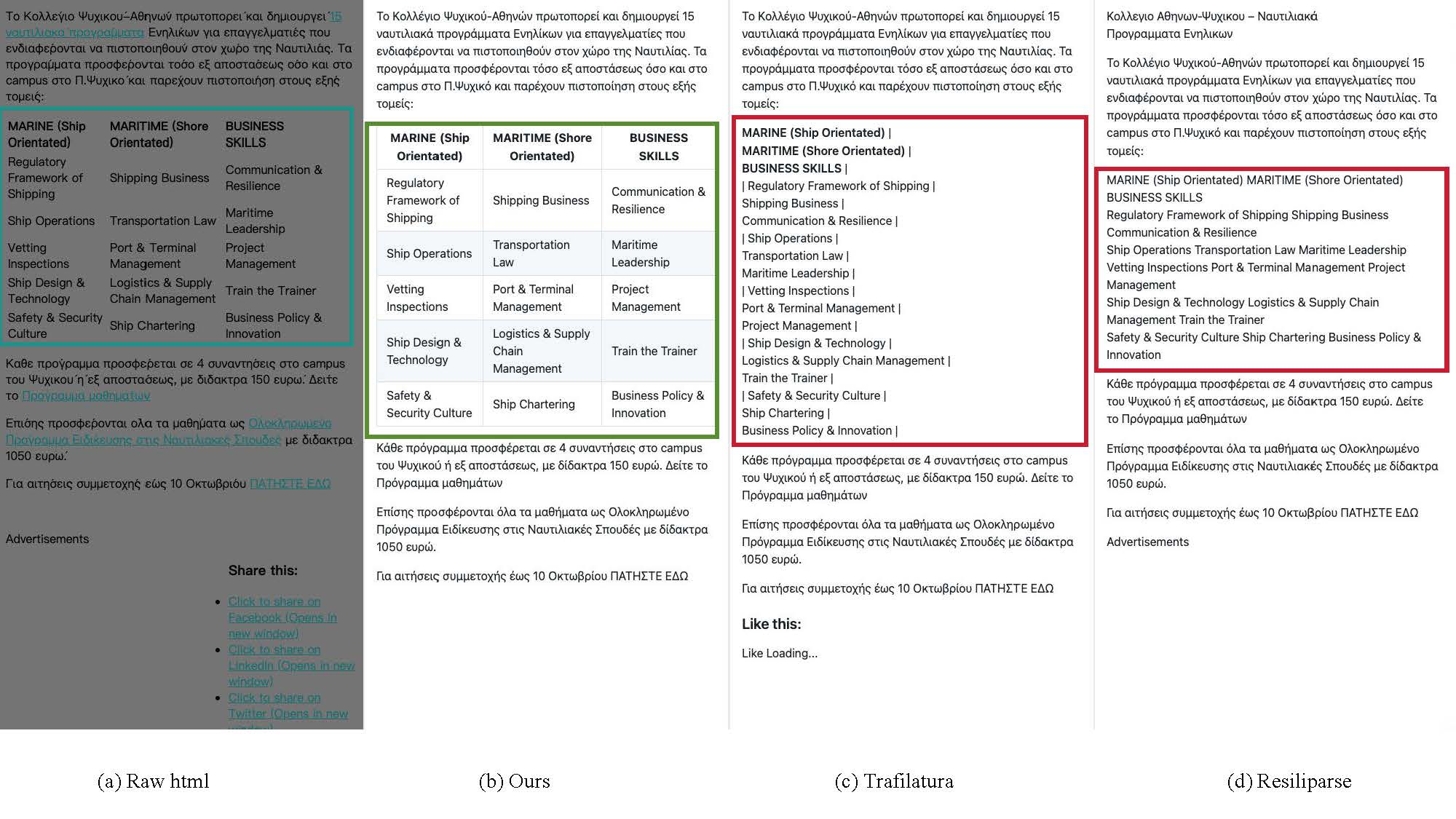
Precise structured elements
High-fidelity extraction of code blocks, mathematical formulas, and complex tables from real-world web pages, preserving syntax, formatting, and structural integrity.
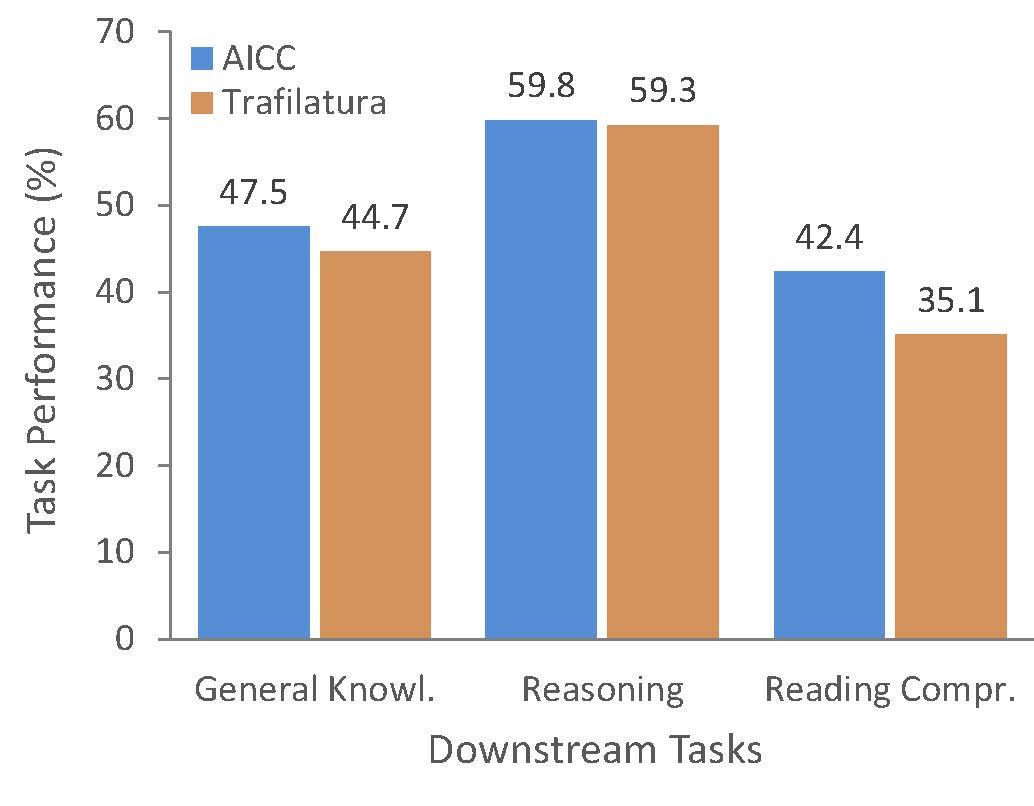
Proven downstream effectiveness
Pretraining a language model on AICC leads to higher accuracy across diverse benchmarks compared to training on datasets extracted with other methods.
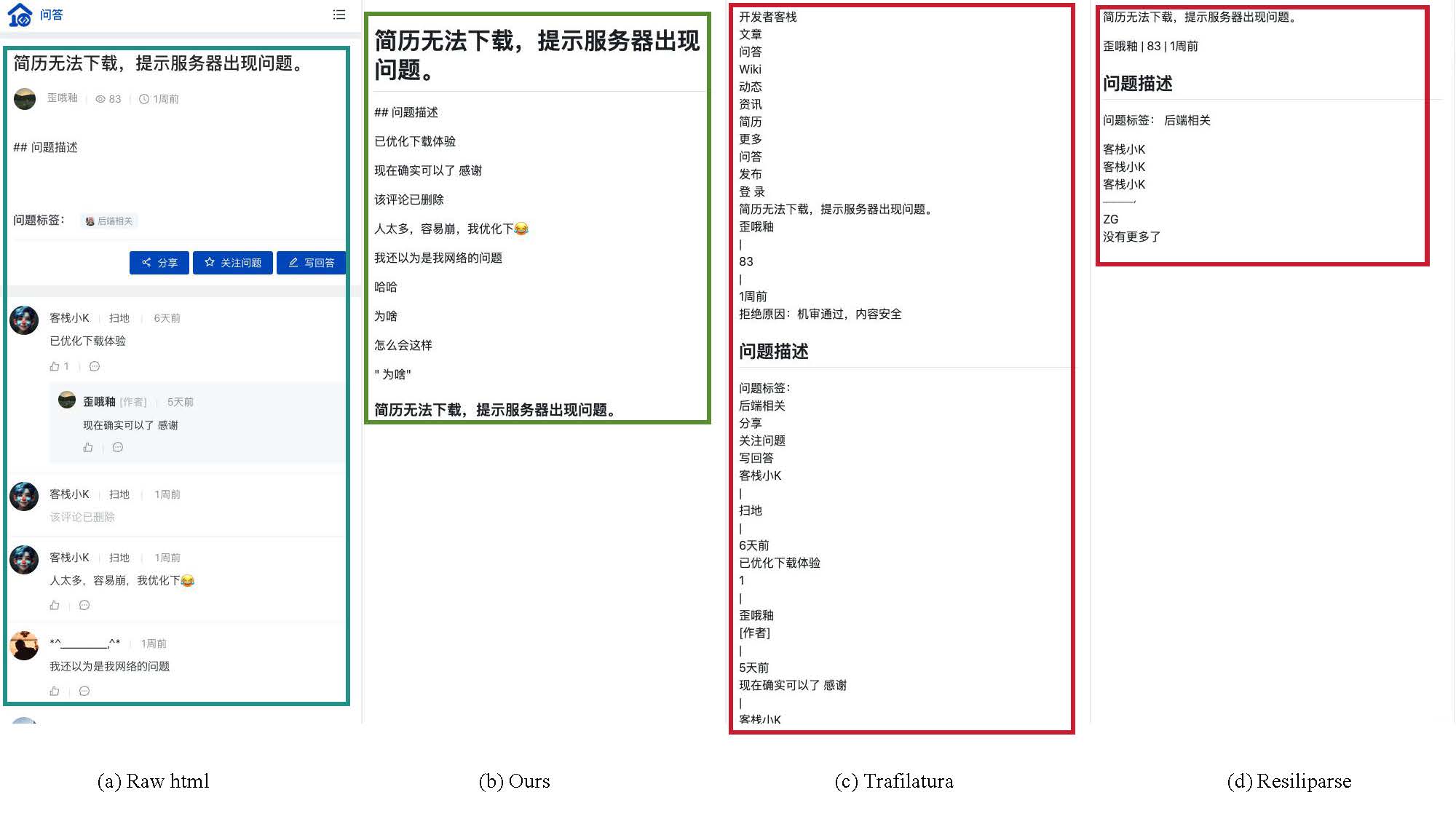
Data samples
See how web data transforms into markdown-formatted content




Try It Yourself
Experience real-time web-data processing with your own HTML
Upload File
No file selectedPlease upload a single HTML file